Histórico da Página
O objetivo desta página é descrever as diversas técnicas e ferramentas que estão à disposição para o monitoramento, suporte e r esolução resolução de problemas do SmartERP. A ordem escolhida para apresentar os itens aqui descritos, remete à linha do tempo da resolução de um problema.
| Índice | ||
|---|---|---|
|
Acesso aos Serviços
O acesso aos serviços aqui descritos devem ser solicitados à área de Segurança da Informação de Cloud.
Visão Geral
O SmartERP Protheus é disponibilizado através de um cluster de Kubernetes.
...
Problemas relacionado ao cluster devem ser destinados ao TOTVS Cloud. Mais detalhes técnicos da arquitetura da solução estão disponíveis em Arquitetura do Smart ERPERP.
Resolução de Problemas
Monitoramento - UptimeRobot
A instalação do SmartERP Protheus possui um processo de auto-cura que resolve alguns problemas nas topologias de maneira automática.
...
À esquerda da tela, uma lista com todos os monitores é exibida. Lembrando, que cada cliente possui dois monitores, um para o environment de homologação, outro para o environment de produção. Ambos apontam para a mesma topologia. No entanto, possuem alguns processos separados. O nome dos monitores é formado pelo código do cliente mais o nome do environment.
Gerenciamento dos Ambientes dos clientes
Para realizarmos o gerenciamento dos ambientes dos clientes, utilizaremos a ferramenta Rancher.
O Rancher é um painel que permite criar, apagar, alterar, escalar containers, fazer load balancer, gerenciar volumes e a rede no Docker.
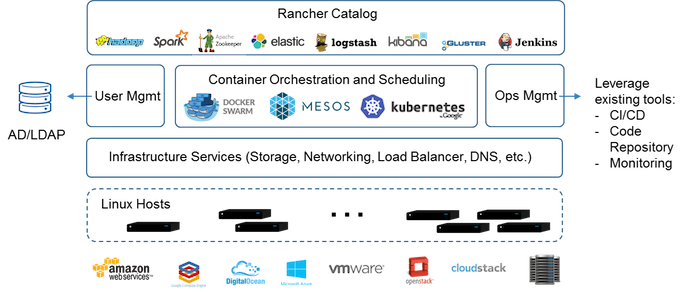
Fonte: http://rancher.com
Principais funcionalidades do Rancher
- Logs de auditoria: Sempre que necessário é possível verificar qual usuário executou uma ação e todos os dados relativos à esta ação. O log de auditoria permite que, além da visibilidade sobre tudo que acontece no cluster, você tenha dados suficientes para eventuais auditorias HIPAA ou PCI DSS, por exemplo.
- API de gerenciamento e webhooks: Tudo falado até aqui e todas outras funcionalidades não faladas, são possíveis de serem executados através da API do Rancher. Via API, é possível escalar seus hosts, serviços, iniciar processos de upgrade (deploy), efetivá-los ou fazer rollback, obter métricas de environments, hosts, stacks, etc. Também é possível configurar URL de webhook para fazer o upgrade de serviços, escalonamento de hosts e serviços.
- Acesso ao Contêiner: Diretamente pela interface você pode acessar os logs do contêiner container (ao invés de entrar host e executar o comando
docker logs XXX -f) ou até mesmo acessar o bash do contêiner container (ao invés dedocker exec -it XXX bash), deixando essa interação bastante dinâmica. Para ter cuidado com os acessos e com chaves secretas, o Rancher tem uma área específica durante a criação de um serviço para a inserção de dados sensíveis como secrets dentro do contêinercontainer.

A ferramenta esta disponível no endereço: https://rancher.gcp.tks.sh/login. Para ter acesso, solicitar ao time SRE Protheus.
...
Tome muito cuidado com esta opção, pois se deletado o POD, todos os processos que dependem dele também estarão inativos.
Logs - logdna (Em análise)
O logdna é um serviço de armazenamento e consulta de logs. Todos os processos da topologia do SmartERP Protheus enviam seus logs para este serviço.
...
Isso significa que para facilitar o processo, basta substituir o parâmetro de consulta apps da URL e recarregar a página para exibir o log desejado. Os parâmetros podem variar, de acordo com os containers e podem assumir os seguintes valores:
...
Para mais detalhes sobre buscas, filtros e afins, consulte a documentação https://docs.logdna.com/docs/getting-started.
Gerenciamento por Linha de Comando - kubectl
Eventualmente será necessário ir mais a fundo na investigação de algum problema. Para isso lançamos mão do kubectl, que é a ferramenta oficial do Kubernetes para realizar qualquer operação no cluster. No entanto o acesso ao cluster via kubectl está limitado à algumas máquinas, sendo assim é necessário solicitar acesso ao time de cloud e SRE.
Quando estiver dentro deste host, poderá executar kubectl e realizar qualquer operação no cluster.
Através da documentação https://kubernetes.io/docs/reference/kubectl/overview/ podemos observar que para listar os pods de um cliente, devemos executar o seguinte comando:
...
O resultado é similar ao obtido no Kubernetic.
Comunicação - Slack
Existe um slack disponível para o time do SmartERP, consulte o time de SRE para o envio do link da comunidade.
O objetivo deste slack é a comunicação dos times envolvidos na operação do serviço.
Além disso, utilizamos o slack como endpoint para alguns filtros de log que são complementares ao serviço de monitoramento descrito anteriormente. Existe um canal neste slack chamado #monitoring que recebe mensagens do logdna quando um determinado log é gerado. Desta maneira, é possível agir proativamente antes do serviço ficar comprometido. Estes filtros ainda devem ser evoluídos e construídos junto com a operação e engenharia do produto.
Problemas Conhecidos
| Problema | Detalhamento | Possíveis Ações |
|---|---|---|
| A página do smartclient html do cliente ou o webservice retorna erro relacionado ao Kong. | O Kong é um servidor web baseado no nginx que é utilizado como proxy reverso para os serviços do Smart ERP. Existe apenas uma instalação de Kong para todo o cluster. Normalmente, esse erro ocorre quando o serviço em questão está fora do ar, sendo assim o Kong não consegue alcançar o endpoint para fazer o proxy. | Utilizar o Kubernetic ou o kubectl para verificar o estado dos pods da topologia em questão. Possivelmente um ou mais pods estarão comprometidos (não Running). Identificar via logs (logdna) o motivo do ocorrido e se for o caso reiniciar o(s) pod(s). |
| O smartclient html do cliente exibe mensagem de falha de conexão na tela. | O |
| SmartERP Protheus utiliza a infraestrutura da AWS/GCP, mais especificamente o datacenter de SP. A latência para este datacenter gira |
| em torno de 50ms. Eventualmente, o problema relatado pode ocorrer se a rede do cliente tiver com um problema adicional de conectividade. | Realizar testes na rede do cliente para comprovar o diagnóstico descrito em detalhamento. | |
| Foi identificado que os containers de uma topologia estão executando restarts sucessivos. | O kubernetes pode reiniciar os containers de uma topologia por conta de alguns problemas. Um deles é que o healthcheck do produto retornou erro. | Verificar junto ao time de produto, com logs obtidos no logdna em mãos, o motivo dos healthchecks terem falhado. |
| O kubernetes pode reiniciar os containers porque o processo em questão está utilizando mais memória do que foi configurado para ele. Quando isso ocorre, o OOMKiller do Linux mata o processo. | Verificar junto ao time de produto, com logs obtidos no logdna em mãos, o porque do consumo excessivo de memória. Eventualmente, a quantidade de memória destinada ao processo em questão pode ser aumentada através da alteração do deployment via Kubernetic ou kubectl. |
| HTML |
|---|
<script>
function linksToBlank(){
var links = document.getElementsByTagName("a");
var l = 0;
for (var i = 0, l = links.length; i < l; i++) {
links[i].target = "_blank";
}
}
window.onload = linksToBlank;
</script> |
Visão Geral
Import HTML Content
Conteúdo das Ferramentas
Tarefas